Every company has a culture, and we’re no exception. In an effort to better understand what makes EverTrue Engineering tick, we took some time amongst ourselves to discuss and clarify what’s most important to us.
Read on →Fun with PAM scripts
Recently I was given the requirement to help build a data exporter tool that would fit with a customer’s existing process which uses SFTP (no comment). Rather than get into the nasty business of managing a whole separate set of credentials, we thought it would be handy if we could get the regular OpenSSH SFTP daemon to authenticate against our existing authentication platform.
Read on →Incident Management
Software companies have outages, be it the entire product or parts of it. Since this is the reality of the situation, here are some concepts that we employ here at EverTrue that have helped us along the way.
Read on →The Right Way to set up NAT in EC2
Considering that it’s one of those things probably every single person using a VPC is going to need to do at some point, it’s amazing that the process for setting up a NAT router in EC2 is so incredibly cumbersome.
Like me, you probably Googled for a quick solution to this problem and found Amazon’s complicated HOWTO on the topic. Then, at some point around hour 3 of trying to parse your way through it, you realized that it doesn’t provide any kind of multi-AZ redundancy, so you went back to Google and found an even longer and more complicated article (from 2013) explaining how to set up a reduntant NAT using CloudFormation and a Bash shell script.
Seriously?
This seemed like the perfect use case for Chef search and a nice, clean Ruby script. This blog post will explain the process of putting that together and (if you just want to get it working) how to make our solution work for you.
Read on →Tuning Guidelines for Apache Spark
At EverTrue, we’ve been building on Apache Spark for almost four months now and have hit just about every wall as it pertains to configuration one could imagine.
One of the surprises we were met with was the sheer amount of configuration options available with Spark. It gives you full control of almost everything you can dream up.
The downside of that is knowing what the important levers to tune and how they relate to one another.
This is a distilled explanation of our experiences thus far.
Read on →ActiveRecord, Standalone Schema Migrations, and Working With Arel

Last Wednesday (March 4th), I gave a two-part presentation to my fellow EverTrue employees on using ActiveRecord’s powerful migration management to handle non-Rails database schema changes and how complex queries can be built using Arel, along with how the responsibilities of ActiveRecord and Arel compare conceptually and practically.
A good part of the company attended (including some marketing, sales, and other non-technical folks), in no small part due to the free taco lunch buffet we were provided (and of course the prospect of an interesting presentation!). The diversity in the audience gave an inherently technical presentation a more widespread appeal, which prompted questions like “How do these changes get surfaced on the front end?”, and “Are our development processes less error-prone because of these changes?”. This sort of exposure helps inform the company and reinforce confidence in our engineers through examples and discussion. It felt good to give this kind of insight into our development organization and how we operate.
Read on →3 Performance Tuning Tips For ElasticSearch
Over the last year, we’ve run into three main tuning scenarios where the defaults were not sufficient. This was primarily due to data growth vs request load. Check them out to avoid any unwanted system crashes.
Read on →Product Hack Week 2014
Releasing The Kraken
This past week EverTrue engineering was given an entire week to deviate from the normal roadmap in order to come up with a hack that would solve a customer pain or help increase their usage of the product.
Engineers had the ability to go solo or form teams.
How We Organized It
We initially sent out an email to the dev team as well as designers notifying them the intended date and rules of engagement.
Prior to the email we set up a trello board and before the kick off it was filled with a ton of really good ideas.
Read on →Setting Up an Archiva Repository and Deploying Artifacts with Jenkins
As the number of internal projects started to grow here at EverTrue, dependency management became a frustrating, time-consuming, and monotonous process.
Our backend framework has a lot of branching dependencies, and this complex network of connections led to several issues:
- Updating a project’s dependencies was a slow and manual process
- This process unnecessarily shifted developer focus, interrupted their workflow, caused confusion, and brought up synch issues
- Every dependency had to be kept open and loaded into Eclipse to be recognized, even if they weren’t being edited at the time
The need for a Maven repository to store and update our project dependencies became quite urgent.
In the interest of streamlining our workflow, we managed to set up a very useful system for keeping our dependencies updated automatically.
As a result, a developer here no longer has to worry about dealing with projects outside the scope of their current project, or working with outdated dependencies.
The solution we found came in the form of a build artifact repository manager called Archiva; it gave us all the right tools to fix our process and is now saving us a fair amount of hassle.
While setting up our repository server we ran into several problems, and compiled a how-to guide on getting everything running. We wanted to share this guide with other developers in the hopes that it makes the process easier for them. Some of the information we found online for our setup was either outdated or buried deep in documentation, spread across several sites. We hope these steps for setting up an Archiva dependency management system with automatically-deployed Jenkins build artifacts are comprehensive, easy to follow, and are as helpful for you as they were for us!
Step-by-step guide:
Read on →Our Dev Manifesto: Testing
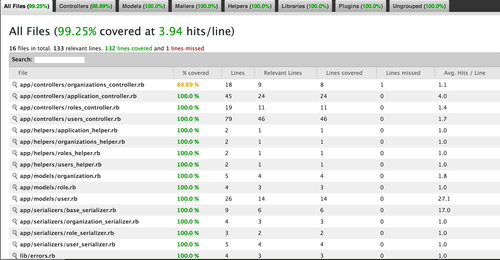
At EverTrue we’re big believers in testing our code, but it wasn’t always that way.
EverTrue is still a very young company and one of the the engineering exercises that often gets forgotten is testing. Name your excuse as to why but the storyline is all too familiar. You have a small amount of resources and time and some things have to get cut.
Read on →